Audio samples from "IMPROVING FEW-SHOT MULTI-SPEAKER TEXT-TO-SPEECH ADAPTIVE-BASED WITH EXTRACTING MEL-VECTOR (EMV) FOR VIETNAMESE"
Paper : arXiv
Authors : Author's name here
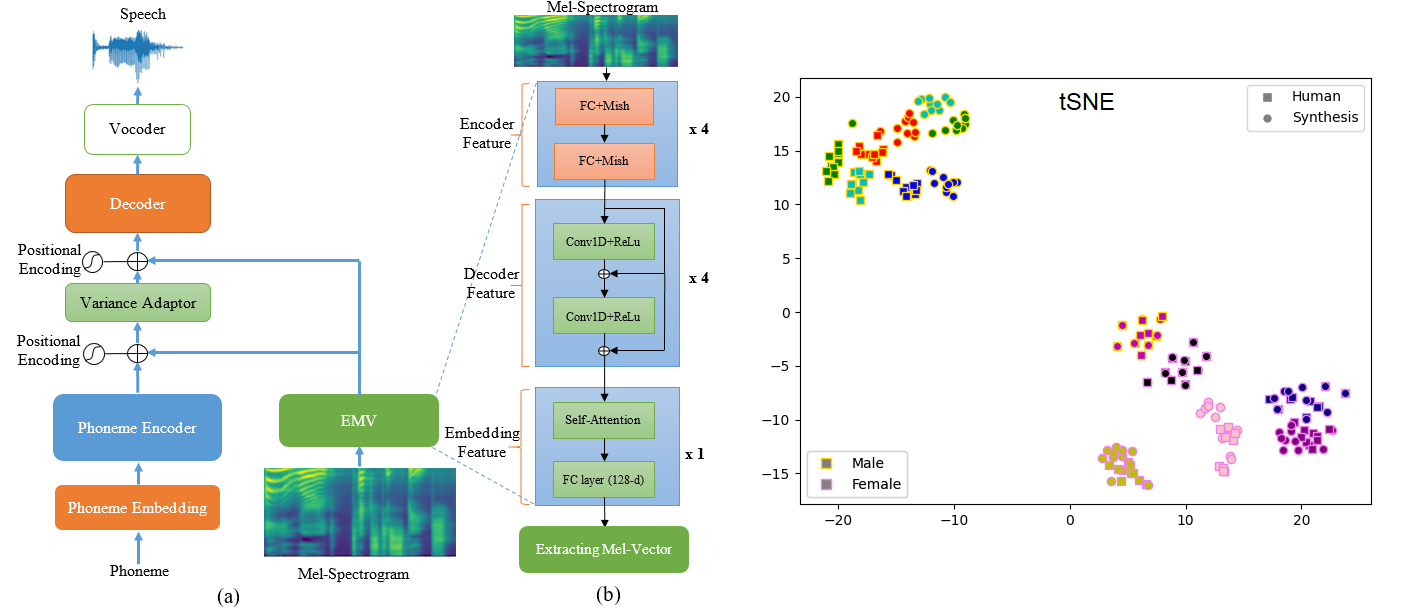
Abstract : Train a multi-speaker text-to-speech model requires multiple speakers' voices to generate an average speech model. However, the average speech synthesis model will be distorted or averaged, resulting in low quality if the new speaker's voice has too little data to train. The existing methods require fine-tuning the model; otherwise, the model will achieve low adaptive quality. However, for synthesis voice to achieve high-quality adaptive, at least thousands of fine-tuning steps are required. To solve these issues, in this paper, we propose a Vietnamese multi-speaker TTS adaptive-based technique that synthesizes high-quality speech and effectively adapts to new speakers, with two main improvements: 1) Propose an Extracting Mel-Vector (EMV) architecture with three components, the encoder-decoder-embedding feature, which enables complete learning of speaker features with Mel-spectrograms as input for few-shot training and; 2) A continuous-learning technique called "data-distributing" preserves the new speaker's characteristics after many training epochs. Our proposed model outperformance the baseline multi-speaker synthesis model and achieved a MOS score of 3.8/4.6 and SIM of 2.6/4 with only 1 minute of the target speaker's voice.
4 minutes
| Groundtruth | Baseline | with EMV vs Data-distributing | |
|---|---|---|---|
| Audio 1 | |||
| Audio 2 | |||
| Audio 3 | |||
| Audio 4 | |||
| Audio 5 |
1 minutes
| Groundtruth | Baseline | with EMV vs Data-distributing | |
|---|---|---|---|
| Audio 1 | |||
| Audio 2 | |||
| Audio 3 | |||
| Audio 4 | |||
| Audio 5 |
© Voice Lab